AI in Healthcare
See Also
Improving Medical AI Accuracy (3 minute read)
MedLFQA is a new benchmark dataset designed to improve the factual accuracy of long-form responses from large language models in the medical field. OLAPH is a framework that trains LLMs to reduce inaccuracies by using automatic evaluations and preference optimization.
- Eureka Health - The world’s first AI doctor (currently specializes in thyroid and diabetes).
- HealthKey - Turn 100s of medical records into a simple patient outline.
Trustworthiness in Medical Models (18 minute read)
CARES is a comprehensive framework that evaluates the trustworthiness of Medical Large Vision Language Models (Med-LVLMs).
Diabetic Retinopathy Detection (14 minute read)
Researchers have developed a novel framework that improves the grading of Diabetic Retinopathy (DR), a condition that can lead to visual impairment.
Awesome Foundation Models for Advancing Healthcare is a huge Github repo summary of all Healthcare-related LLMs. Published as He et al. (2024)
AI Use Cases (from Rock Health): recommendation for how to prompt for better results:
Eric Topol surveys Medical Scans
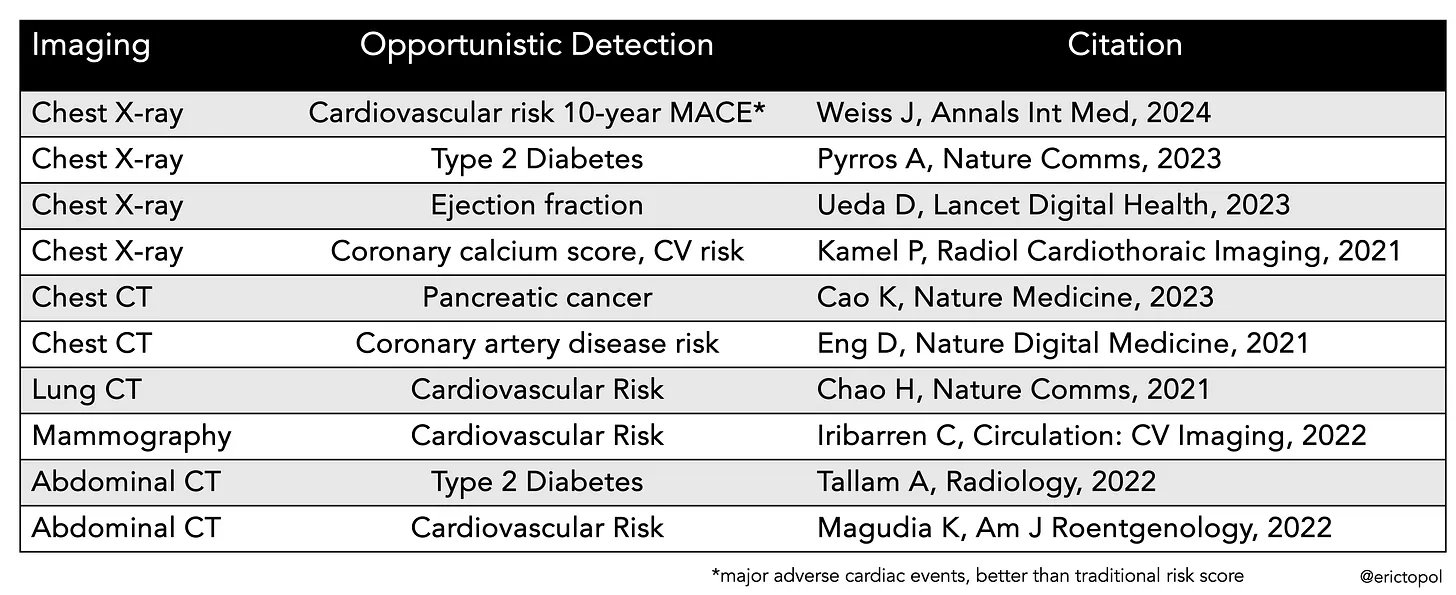
This is a largely unanticipated windfall of A.I. applied to medical imaging—the ability to use machine eyes to uncover what human experts can’t see, markedly enriching potential outputs of medical scans in the future.
CLIP in Medical Imaging: A Comprehensive Survey
Contrastive Language-Image Pre-training (CLIP), a straightforward yet effective pre-training paradigm, successfully introduces semantic-rich text supervision to vision models and has demonstrated promising results in various tasks due to its generalizability and interpretability.
Zhao et al. (2023)
MedAgent: Collaborators for Zero-shot Medical Reasoning

Overview
Read Eric Topol’s Sept 15, 2023 All Eyes on Medical A.I. review of AI used in randomized trials, a major foundation model using retinal images, medical diagnoses and conversations, and life science applications.
He also published an overview in Science: “As artificial intelligence goes multimodal, medical applications multiply”: where we stand with the progress in deep learning, transformer models, and multimodal A.I. It has extensive links to many of the relevant papers and emphasizes critical caveats along with the exciting momentum and opportunities that we’re seeing.
Personal Science Tips
See PS Week 240222 AI Revisited
Personal Science - Daily Notes: an example prompt that helps me with self-tracking
I document my experience with Medical Chat Examples
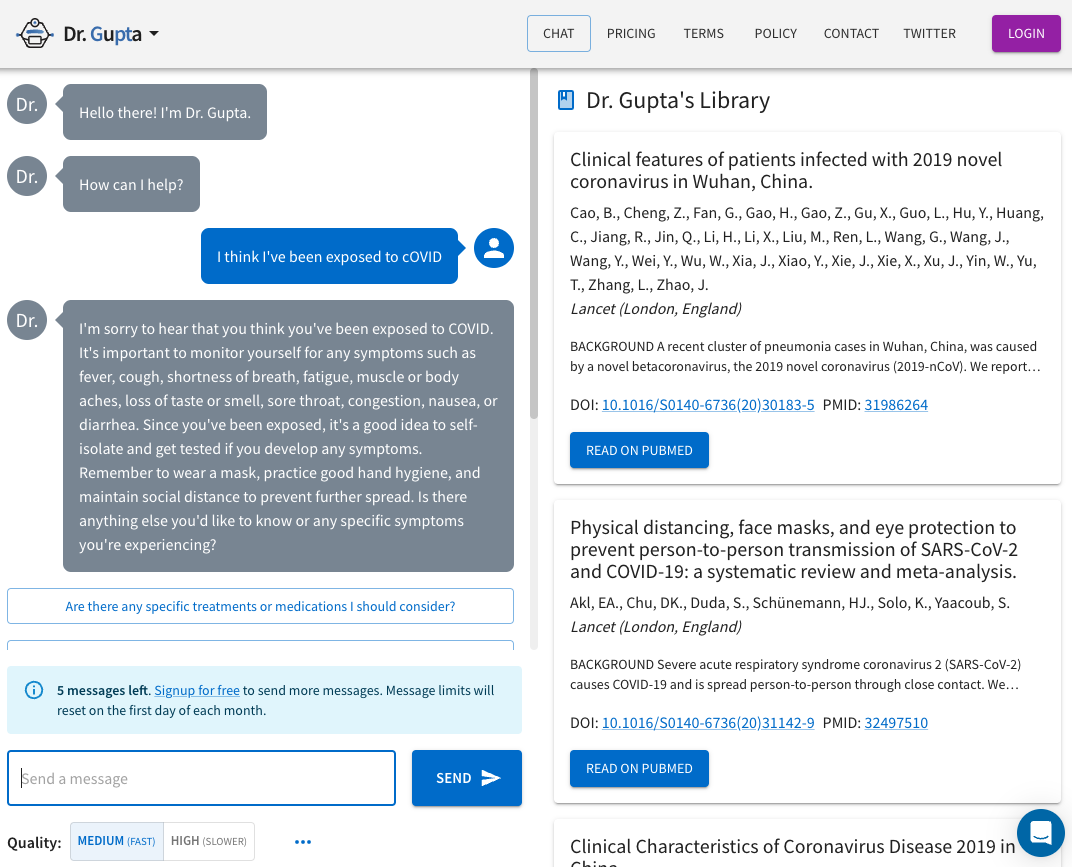
DrGupta.AI is a medical front-end to ChatGPT that specializes in medical advice. Enter your vital signs, including blood tests results, and ask away. Free for up to 12 messages/month, or $20 for unlimited. Dr.Gupta VET offers something similar for your pet.
If you’re a subscriber to ChatGPT, you can try the HouseGPT chatbot. It pretends to be one of those maverick doctors on the old TV series House M.D. Enter your patient details and it tries to offer a diagnosis, generally something less obvious than your typical doctor. Worth trying for tough cases. See Patrick Blumenthal’s post on X for an example.
Our friends at OpenCures have been running a GPT4-based AI Chat for a while. Create an account, upload some of your data, and ask whatever health questions you like.

A post at the Society for Participatory Medicine describes a use-case for ChatGPT in healthcare. A patient converted his lengthy patient record into a useful, actionable summary.
Matthew Sakumoto wrote tips for using ChatGPT as an internal medicine clinician. His tips are fairly generic (e.g. use voice recognition to quickly write notes and then summarize; automate writing authorization letters to carriers, etc.) but might be a good overview for somebody just getting started.
Medical Prompting Meskó (2023) : the current state of research about prompt engineering and, at the same time, aims at providing practical recommendations for the wide range of health care professionals to improve their interactions with LLMs.
Fitness band WHOOP introduced WHOOP Coach, their AI-powered assistant. (see @willahmed)
News
CASE STUDY: How AI Can Help Cure Rare Diseases via community.openai

The President of the American Medical Association enunciates its policy on ChatGPT and the American Medical Association: shows promise, but its many errors indicate it must be approached cautiously. Quoted from an article by the Today Show of a “A boy saw 17 doctors over 3 years for chronic pain. ChatGPT found the diagnosis”)
Manathunga and Hettigoda (2023)
Our proposed alignment strategy for medical question-answering, known as ‘expand-guess-refine’, offers a parameter and data-efficient solution. A preliminary analysis of this method demonstrated outstanding performance, achieving a score of 70.63% on a subset of questions sourced from the USMLE dataset.
Wornow et al. (2023)
A recent paper published in npj Digital Medicine evaluates 84 foundation models (FM) trained on non-imaging EMR data (e.g. clinical text and/or structured data) to provide a systematic review of the strengths and limitations of LLMs in healthcare to date. The review found that most clinical FMs are being evaluated on tasks that provide little info on the potential advantages of FMs over traditional ML models. The researchers call for broader improved evaluations of these models in order to unlock the full potential of FMs in healthcare.
Microsoft works with pathology startup Paige to build an image-based model to detect cancer.
AI passes medical exams
Microsoft’s Harsha Nori and others under Eric Horvitz Nori et al. (2023)
March 2023: how GPT4 does on medical issues

But note that OpenAI’s claim about similar performance in its legal abilities appears to be over-inflated. Re-evaluating GPT-4’s bar exam performance re-ran OpenAI’s claimed 90% score on the Uniform Bar Exam and found actual performance closer to 69%.
Medical AI
and One in five GPs use AI such as ChatGPT for daily tasks, survey finds : Doctors are using the technology for activities such as suggesting diagnoses and writing letters, according to a survey published in BMJ Health and Care Informatics, spoke to 1,006 GPs.
Microsoft and radiology
Eric Topol discusses AI-supported colonoscopy
Eric Topol Discusses AI Snake Oil
DoctorGPT is an open-source, offline Llama 2-based LLM that can pass the US Medical Licensing Exam. It’s 3GB, and available for iOS, Android, and Web. You have to train it yourself, which takes about 24 hours on a paid instance of Google CoLab Pro ($10)
see @sirajraval
NYTimes Gina Kolata quotes
Dr. Rodman and other doctors at Beth Israel Deaconess have asked GPT-4 for possible diagnoses in difficult cases. In a study released last month in the medical journal JAMA, they found that it did better than most doctors on weekly diagnostic challenges published in The New England Journal of Medicine Kanjee, Crowe, and Rodman (2023)
GPT-4 and Medicine
Emergence of General AI for Medicine 1-hr talk by Microsoft Peter Lee at U-Washington showing incredible examples of GPT-4 solving complex medical problems. In the end he proposes that maybe the concept of “app” or “program” will go away, as we start getting computers to simply do the task.
GPT-4 can do this incredible transformation of a doctor’s exam, turning it into FHIR-formatted data required for reimbursement. The payer then can take the FHIR data and convert into their internal processes. But at some point, you wonder why you bother with that FHIR step. Why not do everything straight in natural language?
Peter Lee talks more in a Microsoft podcast
The AI Revolution in Medicine book by Peter Lee Lee, Goldberg, and Kohane (2023) (see my review at Personal Science)
and their NEJM article Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine from Mar 2023 Lee, Bubeck, and Petro (2023)
and my notes on their book: [book] The AI Revolution in Medicine_ GPT-4 and Be by Peter Lee (Microsoft)
#youtube #podcast
Rao et al. (2023) ran ChatGPT through 36 published vignettes used for assessing doctors and found an overall accuracy rate above 70%. It’s lowest performance: generating an initial differential diagnosis (60%)
Gina Kolata in the New York Times A.I. Chatbots Defeated Doctors at Diagnosing Illness refers to a study by Dr. Adam Rodman, an expert in internal medicine at Beth Israel Deaconess Medical Center in Boston that found ChatGPT-4 outperformed doctors.
Goh et al. (2024)
How Accurate?
In a new study, scientists at Beth Israel Deaconess Medical Center (BIDMC) compared a large language model’s clinical reasoning capabilities against human physician counterparts. The investigators used the revised-IDEA (r-IDEA) score, which is a commonly used tool to assess clinical reasoning.
The study entailed giving a GPT-4 powered chatbot, 21 attending physicians, and 18 resident physicians 20 clinical cases to establish diagnostic reasoning for and work through. All three sets of answers were then evaluated using the r-IDEA score. The investigators found that the chatbot actually earned the highest r-IDEA scores, which actually proved to be quite impressive with regards to diagnostic reasoning. However, the authors also noted that the chatbot was “just plain wrong” more often.
Stephanie Cabral, M.D., the lead author of the study, explained that “further studies are needed to determine how LLMs can best be integrated into clinical practice, but even now, they could be useful as a checkpoint, helping us make sure we don’t miss something.” Summarily, the results indicated sound reasoning by the chatbot, however significant mistakes as well; this further bolsters the idea that these AI powered systems are best fit (atleast at their current maturity levels) as tools to augment a physician’s practice, rather than replace a physician’s diagnostic capabilities.
A randomized study using Mass General case records diagnosis compared performance by 20 experienced internal medicine physicians (average time in medical practice of 9 years) with that of a large language model (LLM).which included the correct diagnosis, for over 300 CPC (clinicopathological conferences).

McDuff et al. (2023) via Eric Topol
Google Personal Health LLM is designed to integrate FitBit with personal health coaching and more. It’s built on Gemini models and “fine-tuned on a de-identified, diverse set of health signals from high-quality research case studies”.
For example, this model may be able to analyze variations in your sleep patterns and sleep quality, and then suggest recommendations on how you might change the intensity of your workout based on those insights.
from Healthcaredive - Google Cloud has launched a tool backed by generative artificial intelligence that allows clinicians to search for information across patient notes, scanned documents and other clinical data. - That tool, called Vertex AI Search for Healthcare, is now available for Google Cloud customers, the tech giant announced Tuesday during the HIMSS conference in Las Vegas.
Google Med-Gemini
May 1, 2024: Google Introduces Med-Gemini Family of Multimodal Medical AI Models, Claimed to Outperform GPT-4 > Med-Gemini-S 1.0, Med-Gemini-M 1.0, Med-Gemini-L 1.0, and Med-Gemini-M 1.5. All of the models are multimodal and can provide text, image, and video outputs. The models are also integrated with web search, which the company claims has been improved through self-training to make the models “more factually accurate, reliable, and nuanced” when showing results for complex clinical reasoning tasks.
and see : X summary by Google’s Jeff Dean and this
Delighted to share ✨Med-Gemini✨ - our new family of multimodal models for medicine unlocking new possibilities for health - https://t.co/oemI52WBou
— Alan Karthikesalingam (@alan_karthi) April 30, 2024
More accurate multimodal conversations about medical images🩻, surgical videos📽️, genomics🧬, ultra-long health records📚, ECGs🫀… pic.twitter.com/gZ6WT4Mw3y
Apr 2024 Capabilities of Gemini Models in Medicine
Described in this preprint with Natarajan Saab et al. (2024)
Jan 2024 IEEE Spectrum: The DeepMind team turns to medicine with an AI model named AMIE
Trained on 100K real doctor-patient dialog transcripts, ICU medical notes, and thousands of questions from USMLE.
To fill in gaps from the data, lead author Vivek Natarajan created a “virtuous cycle”
“The environment included two self-play loops—an ‘inner’ self-play loop, where AMIE leveraged in-context critic feedback to refine its behavior on simulated conversations with an AI patient simulator, and an ‘outer’ self-play loop where the set of refined simulated dialogues were incorporated into subsequent fine-tuning iterations,” Natarajan says. “The resulting new version of AMIE could then participate in the inner loop again, creating a virtuous continuous learning cycle.”
AI Beats Humans in Medical Care
Jan 2024 Nature says Google AI has better bedside manner than human doctors — and makes better diagnoses
20 actors simulating patients tested 149 clinical scenarios evaluated by both physicians and a Google LLM.
The AI system matched or surpassed the physicians’ diagnostic accuracy in all six medical specialties considered. The bot outperformed physicians in 24 of 26 criteria for conversation quality, including politeness, explaining the condition and treatment, coming across as honest, and expressing care and commitment.
Tu et al. (2024)
Google Med-PaLM
See July 2023 overview by Chris McKay at Maginative.com
Google is planning Multimodal Medical AI
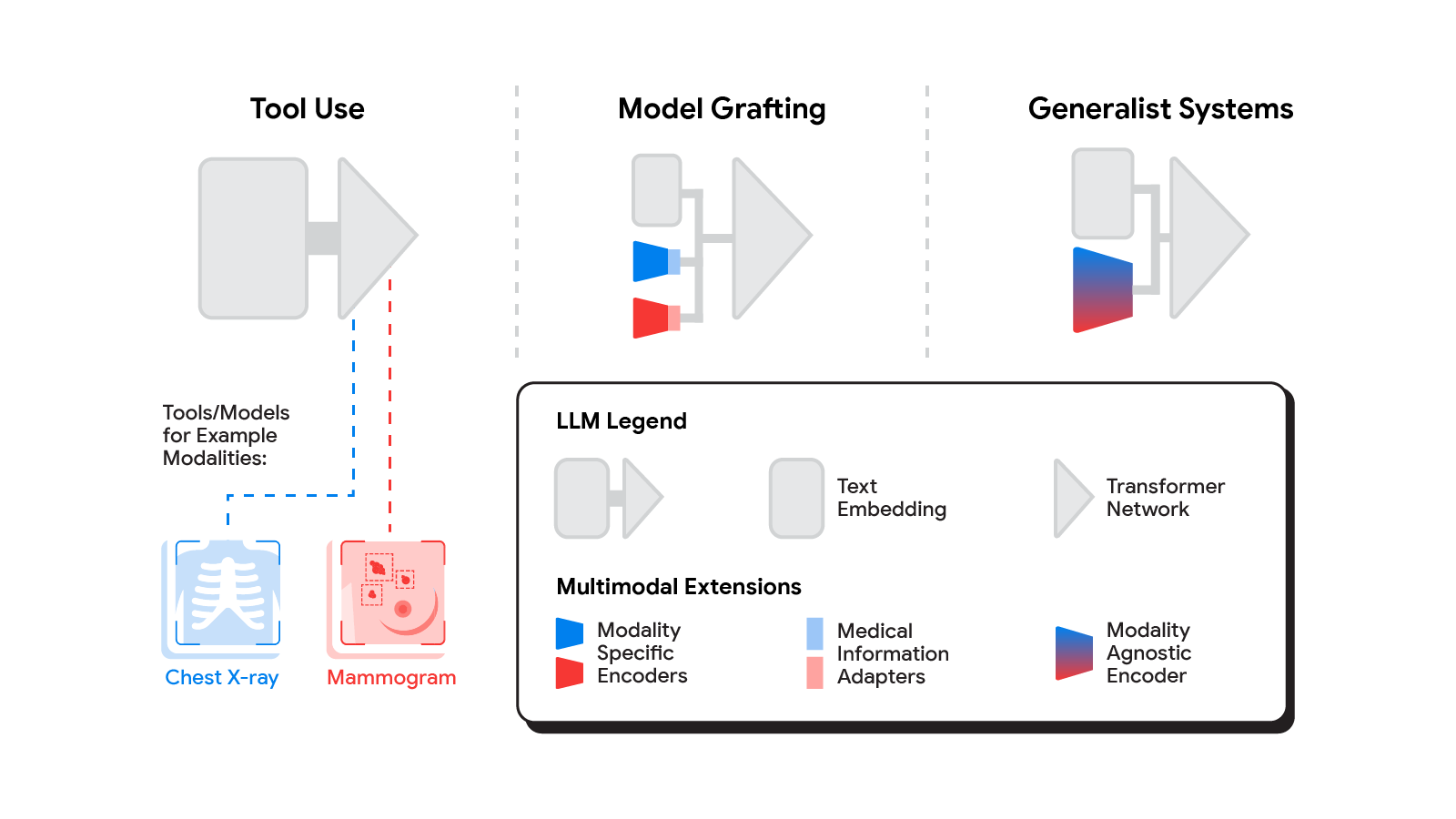
third paper in this area, “Towards Generalist Biomedical AI”, rather than having separate encoders and adapters for each data modality, we build on PaLM-E, a recently published multimodal model that is itself a combination of a single LLM (PaLM) and a single vision encoder (ViT). In this set up, text and tabular data modalities are covered by the LLM text encoder, but now all other data are treated as an image and fed to the vision encoder.
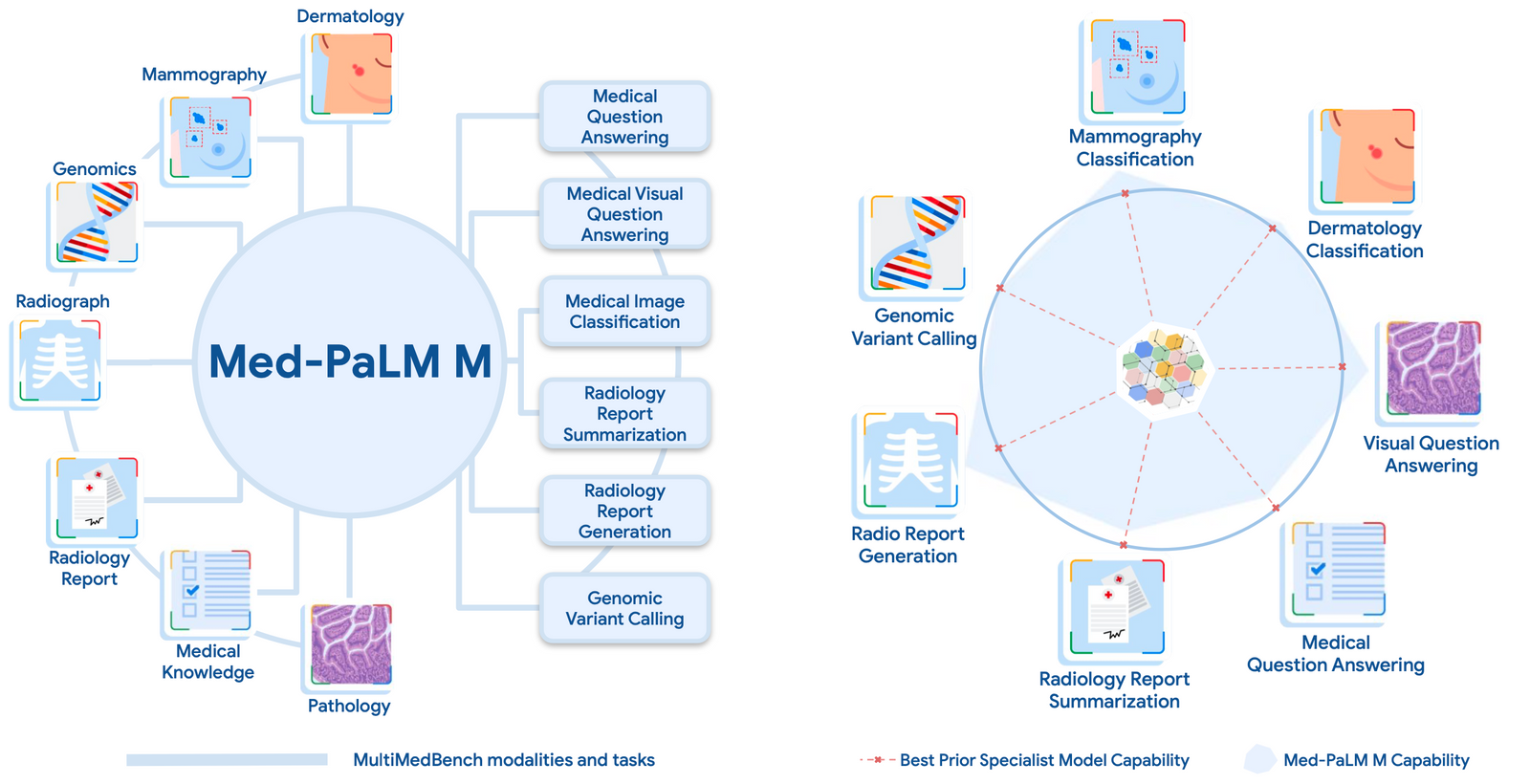
Google’s medical AI MedPaLM 2 scored 86.5% on a medical exam (the typical human passing score is around 60%).
Towards Expert-Level Medical Question Answering with Large Language Models
Med-PaLM 2 scored up to 86.5% on the MedQA dataset
and it includes special techniques to “align” to “human values” on equity.
Med-PaLM harnesses the power of Google’s large language models, which we have aligned to the medical domain and evaluated using medical exams, medical research, and consumer queries. Our first version of Med-PaLM, preprinted in late 2022 and published in Nature in July 2023, was the first AI system to surpass the pass mark on US Medical License Exam (USMLE) style questions. Med-PaLM also generates accurate, helpful long-form answers to consumer health questions, as judged by panels of physicians and users.We introduced our latest model, Med-PaLM 2, at Google Health’s annual health event The Check Up, in March, 2023. Med-PaLM 2 achieves an accuracy of 86.5% on USMLE-style questions, a 19% leap over our own state of the art results from Med-PaLM. According to physicians, the model’s long-form answers to consumer medical questions improved substantially. In the coming months, Med-PaLM 2 will also be made available to a select group of Google Cloud customers for limited testing, to explore use cases and share feedback, as we investigate safe, responsible, and meaningful ways to use this technology.
2023-07-24 8:38 AM
Google in Nature (2023): Large language models encode clinical knowledge Singhal et al. (2023)
we present MultiMedQA, a benchmark combining six existing medical question answering datasets spanning professional medicine, research and consumer queries and a new dataset of medical questions searched online, HealthSearchQA. We propose a human evaluation framework for model answers along multiple axes including factuality, comprehension, reasoning, possible harm and bias. In addition, we evaluate Pathways Language Model1 (PaLM, a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM2 on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA3, MedMCQA4, PubMedQA5 and Measuring Massive Multitask Language Understanding (MMLU) clinical topics6), including 67.6% accuracy on MedQA (US Medical Licensing Exam-style questions), surpassing the prior state of the art by more than 17%.
Rating Accuracy
This Feb 2023 paper, Kung et al. (2022) “Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models” concludes
ChatGPT performed at or near the passing threshold for all three exams without any specialized training or reinforcement
But when they compared the general purpose GPT model against one that had been specifically optimized for biomedical data, the accuracy fell.
They speculate that this is because general purpose models tend to come from large pools of what amounts to consensus understanding, whereas specialized data tends to include too many exceptions, often contradictory. Darn personalized medicine!
Paradoxically, ChatGPT outperformed PubMedGPT (accuracy 50.8%, unpublished data), a counterpart LLM with similar neural structure, but trained exclusively on biomedical domain literature.
They speculate that this is because general purpose models tend to come from large pools of what amounts to consensus understanding, whereas specialized data tends to include too many exceptions, often contradictory. Darn personalized medicine!
Healthtech AI Development

Mass General Brigham AI is hosting, the Healthcare AI Challenge a consortium of healthcare institutions that will rank and evaluate AI products in a clinical setting.
via Healthcare Dive
Tools that assist in AI healthtech development:
Health-LLM
A project of MIT and Google researchers
Kim et al. (2024)
This paper investigates the capacity of LLMs to deliver multi-modal health predictions based on contextual information (e.g. user demographics, health knowledge) and physiological data (e.g. resting heart rate, sleep minutes).
Marktechpost summary:
MIT and Google researchers introduced Health-LLM, a groundbreaking framework designed to adapt LLMs for health prediction tasks using data from wearable sensors. This study comprehensively evaluates eight state-of-the-art LLMs, including notable models like GPT-3.5 and GPT-4.

Health-Alpaca model, a fine-tuned version of the Alpaca model, emerged as a standout performer, achieving the best results in five out of thirteen tasks.
LlamaCare: A Large Medical Language Model for Enhancing Healthcare Knowledge Sharing LLamaCare
a fine-tuned medical language model, and Extended Classification Integration(ECI), a module to handle classification problems of LLMs. Our contributions are :
- We fine-tuned a large language model of medical knowledge with very low carbon emissions and achieved similar performance with ChatGPT by a 24G GPU.
- We solved the problem of redundant categorical answers and improved the performance of LLMs by proposing a new module called Extended Classification Integration.
InternistAI is a medical domain large language model trained by medical doctors to demonstrate the benefits of a physician-in-the-loop approach. The training data was carefully curated by medical doctors to ensure clinical relevance and required quality for clinical practice. > > With this 7b model we release the first 7b model to score above the 60% pass threshold on MedQA (USMLE) and outperfoms models of similar size accross most medical evaluations.
Longitudinal Health Records from Picnic Health (X Summary) Read more for a more comprehensive look at LLMD Preprint: https://arxiv.org/abs/2410.12860 Blog: https://picnicai.substack.com/p/introducing-llmd
Other Health
Flare Capital Partners lengthy 10-year-lookback on how healthcare budgets have fared against the initial AI hype. No good summary or conclusions, but it does break down spending by categories like clinical and life sciences.
Streamlining Healthcare Compliance with AI is a step-by-step guide for using LangChain and Unstructured in a RAG architecture to quickly answer questions about insurance policies.
See The dummies guide to integrating LLMs and AIs into EHRs at the healthcaredata substack.
To use data to make a good recommendation to a clinician, you must ask and answer the following questions:
How much data do I need? How do I weigh it? How do I handle new inputs?
Where should my model pull data from?
What is the workflow for clinician interaction?
How do you know if the model was effective?
Medical image segmentation from OpenGVLab.
Policy and Regulation
The US government Medicare office (CMS) announced a rule that Artificial Intelligence cannot be used to deny healthcare.
In an example involving a decision to terminate post-acute care services, an algorithm or software tool can be used to assist providers or MA plans in predicting a potential length of stay, but that prediction alone cannot be used as the basis to terminate post-acute care services.
The imperative for regulatory oversight of large language models (or generative AI) in healthcare article in Nature Digital Medicine by Bertalan Meskó & Eric J. Topol. Meskó and Topol (2023)
Summary of their proposal
- Create a new regulatory category for LLMs
- Provide regulatory guidance for companies and healthcare organizations about how they can deploy LLMs into their existing products and services
- Create a regulatory framework that not only covers text-based interactions but possible future iterations such as analyzing sound or video
- Provide a framework for making a distinction between LLMs specifically trained on medical data and LLMs trained for non-medical purposes.
- Similar to the FDA’s Digital Health Pre-Cert Program, regulate companies developing LLMs instead of regulating every single LLM iteration
Please don’t use ChatGPT for diet advice Foodie magazine Bon Appetit asks basic questions about health diets and doesn’t like the answers. A Techcrunch writer (May 2023) doubled-down and notes:
The dietary advice use case gave me pause, I must say, in light of the poor diet-related suggestions AI like OpenAI’s ChatGPT provides.
A study on exercise advice in the journal JMIR Medical Education Zaleski et al. (2024) compared ChatGPT’s advice for 26 populations identified in the American College of Sports Medicine’s Guidelines for Exercise Testing and Prescription
#fitness #exercise
A16Z says the US Government Should Let AI Make Us Healthier Empower the FDA with AI as a tool in handling investigational new drug (IND) applications
create a novel Software as Medical Device approval pathway capable of reviewing applications that leverage both foundational LLMs and specialty, smaller models. To do this, the Agency will need to require a baseline approval of the foundational model, and a less rigorous review for the smaller, specialty models, which will be subject to postmarket surveillance.
also equity, bias, blah blah
Not worth reading
Anderer S, Hswen Y. AI Developers Should Understand the Risks of Deploying Their Clinical Tools, MIT Expert Says. JAMA. Published online February 07, 2024. doi:10.1001/jama.2023.22981
A woke “expert” thinks AI models should misrepresent their data if that what it takes to ensure white men don’t get treatment.
AI Failures in Medicine
TheMessenger 2023-08-03 reports ChatGPT Not Reliable for Medical Information from researchers at UC Riverside
Hristidis et al. (2023)
Google had superior currency and higher reliability. ChatGPT results were evaluated as more objective. ChatGPT had a significantly higher response relevance, while Google often drew upon sources that were referral services for dementia care or service providers themselves. The readability was low for both platforms, especially for ChatGPT (mean grade level 12.17, SD 1.94) compared to Google (mean grade level 9.86, SD 3.47). The similarity between the content of ChatGPT and Google responses was rated as high for 13 (21.7%) responses, medium for 16 (26.7%) responses, and low for 31 (51.6%) responses.
When Physicians Go Head-to-Head with Large Language Model (Evernote)
They also used a reasoning technique sometimes referred to as pre-mortem examination. Essentially, they asked themselves: What would happen once a specific diagnosis is made and acted upon? What are the consequences, good and bad?
The scenario dramatically illustrates the difference between LLMs trained on the general content of the internet and the “database” residing within the brain of a veteran cardiologist with decades of clinical experience and expert reasoning skills.
That is not to suggest that LLMs have no place in medicine. One approach that has merit is retrieval-augmented generation (RAG), which can control model knowledge and reduce hallucinations.
They suggest an AI specifically trained on trusted information sources, though it’s unclear how that would be different from one widely trained.
My Tweet > A cardiologist dissects the GPT-4 analysis and shows how a veteran doctor can see nuance that GPT can’t. Yes, both have the same initial diagnosis, but the veteran thinks ahead about the treatment consequences.
How the various models are evaluated is important too: see How Good Is That AI-Penned Radiology Report? Yu et al. (2023)
The researchers examined the agreement between automated evaluation metrics and radiologists’ judgments on errors in radiology reports, using the Kendall rank correlation coefficient (tau b) for comparison. The focus is on 50 radiology studies, assessing both total and significant errors found by radiologists. The metrics RadGraph F1 and BERTScore emerged as the most aligned with radiologist opinions. Specifically, RadGraph demonstrated a moderate level of agreement, with a tau value of 0.515 for all errors and 0.531 for significant errors, indicating a decent correlation between the automated metrics and the radiologists’ assessments. These findings suggest that RadGraph F1 and BERTScore could be useful tools in evaluating the accuracy of radiology reports, potentially aiding radiologists by automating the identification of errors. The study highlights the potential of automated metrics to complement traditional radiologist evaluations, enhancing the quality control of radiology reports.
Biology, Biotech, Genomics
References
The Future of Digital Health by Bertalan Meskó at Medical Futurist is a daily newsletter of AI-related medical news.
O’Reilly Books (link) publishes LLMs and Generative AI for Healthcare by Kerrie Holley and Manish Mathur. I only glanced at the early release version, but it looks like a generic overview (“LLMs are generally great but keep the following things in mind”) that you could probably get from a well-written blog post. The chapter on future predictions (“Whispers of Tomorrow”) speculates about a 2030s-era world where AI designs and arranges manufacture of new medical devices and where software engineering is replaced by natural language “conversational interface” based apps that self-optimize and adapt as needed. #book


New AI-focused speciality publication by NEJM. Started publication Jan 2024:
See Current Issue including Use of GPT-4 to Diagnose Complex Clinical Cases
Also see China and AI